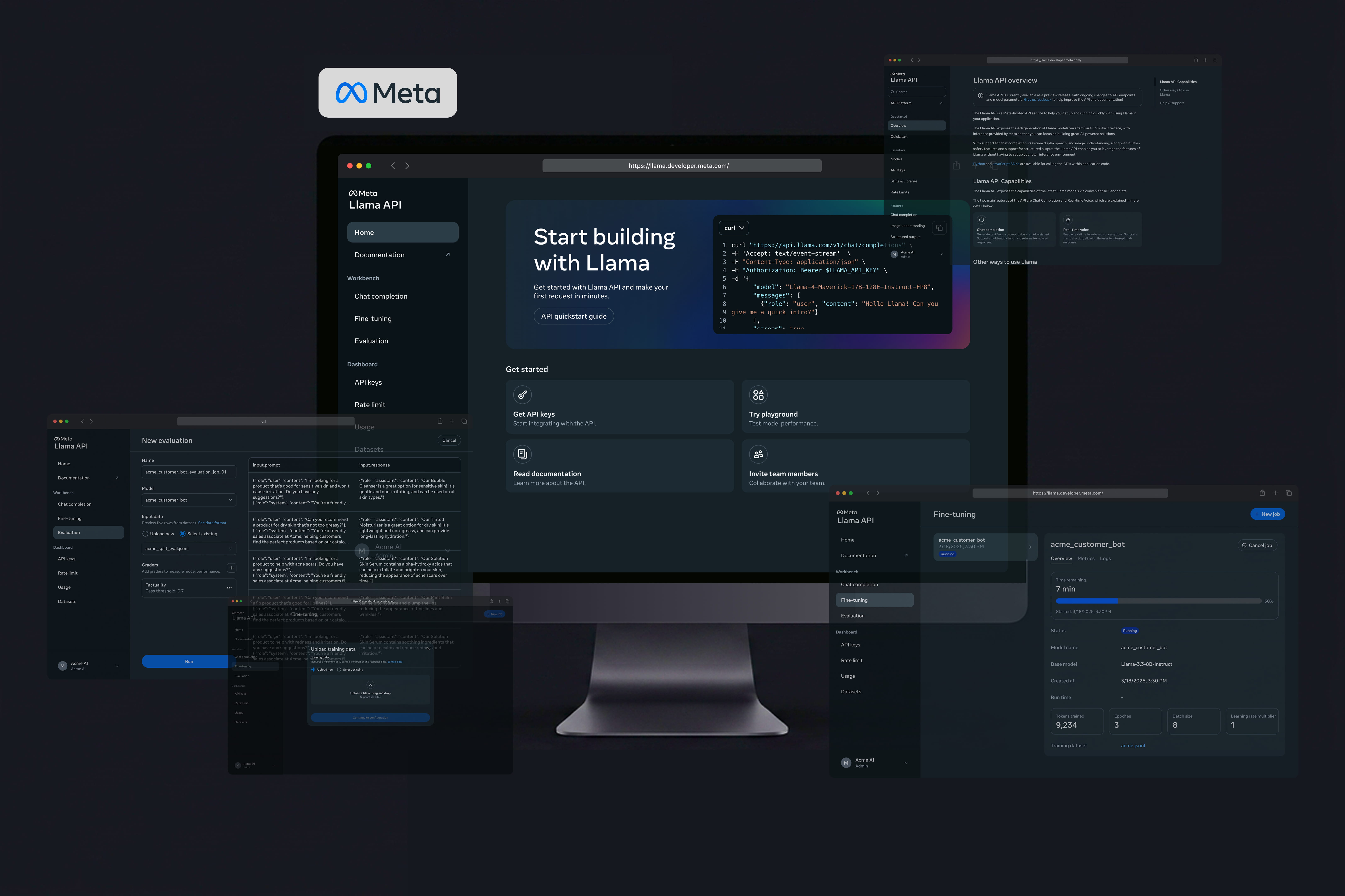
Meta Llama API Platform
Making model training easier to understand
Impact
I shipped end-to-end fine-tuning and evaluation on the Meta Llama API Platform.
Customer outcomes
AT&T — ~10× faster insights, ~90% lower cost on call summarization. (source)
Spotify — +14% domain-specific accuracy. (source)
3.8M
Livestream viewers · LlamaCon keynote
20K+
20K+ signups in the first two months
6 weeks
Shipped the core experience in 6 weeks
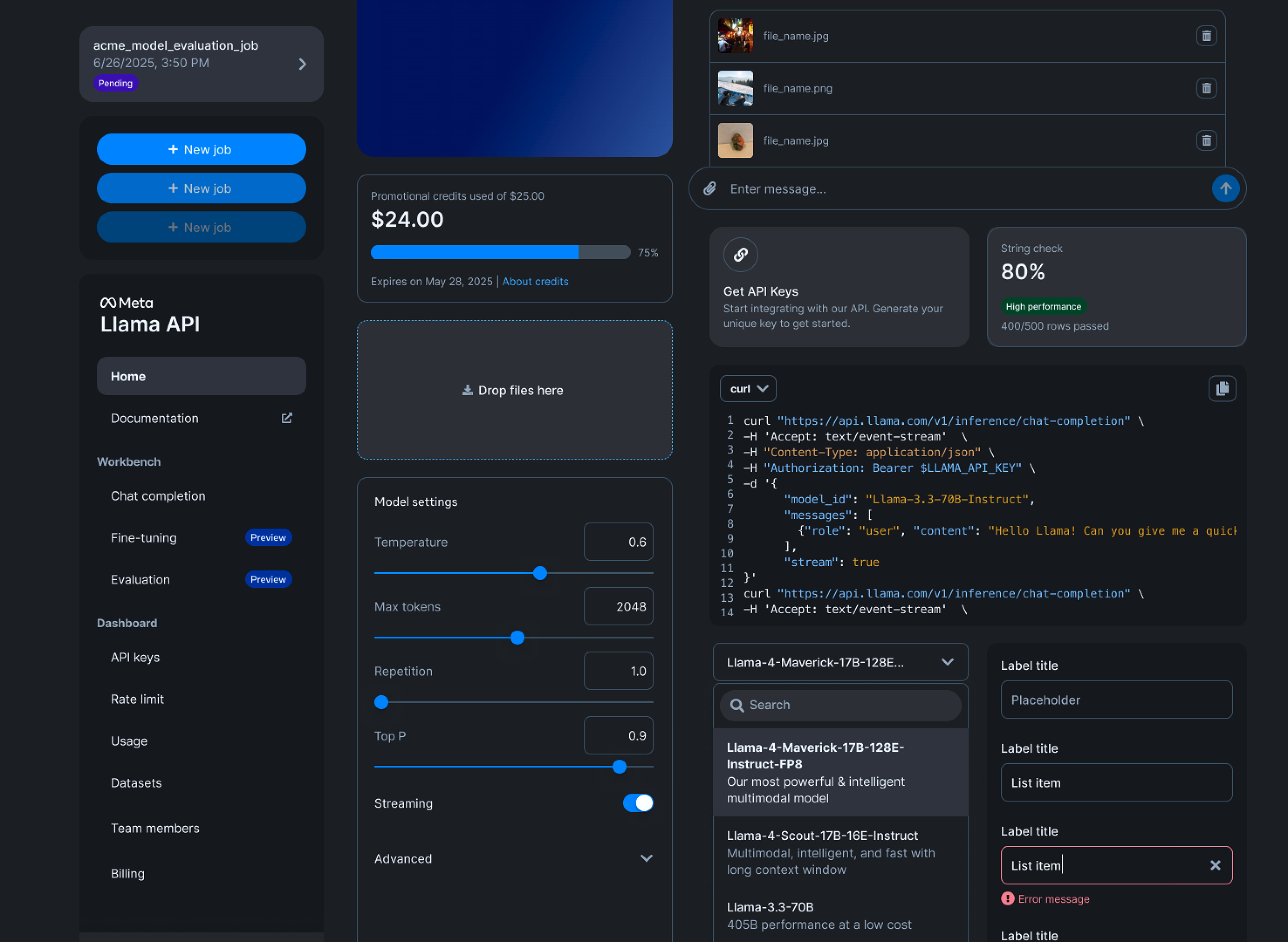
The problem
Fine-tuning runs easily but stays hard to understand.
Most users are small businesses and students without ML backgrounds—they want cheaper, faster models, not more knobs.
In practice:
- training feels opaque
- evaluation feels unclear
- results stay hard to trust or improve
Core insight
People get stuck when they can't answer:
- Did this actually improve anything?
- Where did it fail?
- What should I change next?
The goal isn't to show every control—it is to keep the path from start to finish easy.
Why fine-tune?
Fine-tuning helps when long prompts get expensive, slow, or inconsistent. Teach the model once, then reuse that behavior at lower cost.
The workflow: upload examples, split data, train, evaluate, iterate.
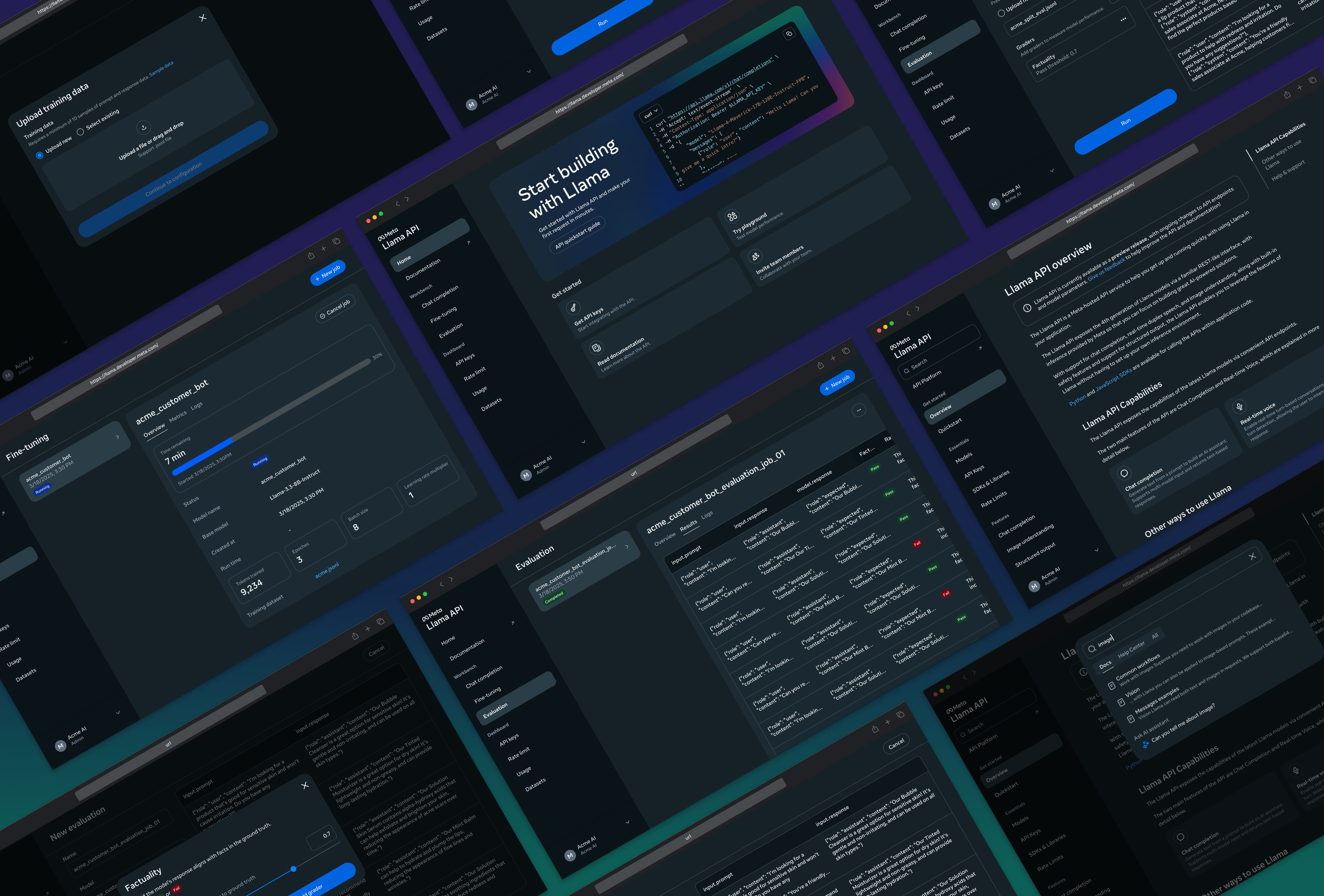
A real example
For a customer-support task, the model had to turn messy refund requests into consistent answers.
Before fine-tuning, each request needed a long prompt. After fine-tuning, the model learned the tone, format, and policy logic from examples.
Before: base model output
- 4.8s average response time
- $0.021 average cost per response
- structure and tone varied across similar requests

After: fine-tuned model output
- 1.3s average response time (-73%)
- $0.004 average cost per response (-81%)
- format and policy reasoning stayed consistent
Design decisions
Decision 1
Make evaluation part of the workflow upfront
Required a train/eval split up front.
→ Grounds performance in unseen data, not assumptions.
Decision 2
Design for low-friction setup
Designed a guided linear flow with strong defaults—no ML course required.
→ Cuts setup friction and speeds up a first successful run.
Decision 3
Make training progress visible
Surfaced logs and status during training—not a silent spinner.
→ Lowers uncertainty on long jobs and keeps people oriented.
Decision 4
Meet users where they already analyze results
Kept the surface focused on lightweight evaluation results and downloadable model outputs—not dense dashboards.
→ Lets people plug results back into their own AI tools for deeper analysis.
Product principle
The product centers on one clear loop:
Data → Train → Evaluate → Test → Iterate
That meant keeping the surface focused on the core loop, not expanding into dataset management, deep analytics dashboards, or batch inference tooling.
The goal isn't to make fine-tuning easier—it is to make it understandable.